
 Gmail을 이용하다보면 간혹 리스트와 본문에서 보낸 사람의 이름이 깨져보이는 경우가 많습니다. 그것도 불과 얼마전까지 그러지 않다가 그런 것처럼 보입니다. 제 리퍼러에 ‘Gmail 보낸 이 깨져’라는 검색 리퍼러가 들어와 있어서 한번 그 이유를 포스팅해봅니다.
Gmail을 이용하다보면 간혹 리스트와 본문에서 보낸 사람의 이름이 깨져보이는 경우가 많습니다. 그것도 불과 얼마전까지 그러지 않다가 그런 것처럼 보입니다. 제 리퍼러에 ‘Gmail 보낸 이 깨져’라는 검색 리퍼러가 들어와 있어서 한번 그 이유를 포스팅해봅니다.
#20070525 추가.
아래의 문제는 2007년 5월 23일 이후 수신되는 메일에는 또 적용되지 않습니다. 즉, 인코딩셋이 적용되어있지 않은 문자도 정상적으로 표시해주고 있습니다(묘하게도 첨부용량 확대 시점과 맞물려 다시 변경되었네요. 정말 버그일지도 모르겠습니다). 언제 또 다시 변경될지는 모르겠습니다만… 버그라면 이번에는 제대로 패치했길 바랄 뿐입니다.
이 문제는 Gmail의 문자 인코딩 정책이 갈짓자(之)를 그리고 있다는 얘기로 귀결됩니다. Gmail의 정책 변경 방향이 잘못되었다는 것이 아니라, 자꾸 바뀌고, 일관성이 없다는 얘기입니다.
![]()
우선, 위의 목록에서 보시면 하나는 제대로 나오고, 하나는 깨져보이고 있습니다. 이 둘은 둘다 “한글”이며, 다른 메일 서비스에서 보면 둘다 정상적으로 표시되지만, 유독 Gmail에서만 깨져나옵니다. 그렇다면 둘의 차이는 뭘까요? (참고로 위의 À̴Ͻýº 글자는 “이니시스“라는 글자입니다) 그냥 보이는 메일 화면에서는 차이를 알 수 없습니다. 그렇다면 원문 보기를 해야죠. 보낸 사람 이름이 깨진 “이니시스”의 메일을 ①번, 아래 정상적으로 나오는 “한 민신”의 메일을 ②라고 하겠습니다.
①의 원문보기로 들어가서 헤더 부분 중 From을 찾아봅니다. Firefox에서 아래처럼 나옵니다.

후아, 무슨 글자인지 깨져서 도저히 알아볼 수가 없습니다. Firefox > 보기 > 문자 인코딩 > 한국어(EUC-KR)로 지정해봅니다.

이렇게 하면 저 깨진 글자가 제대로 나옵니다. 즉, 저 헤더의 보낸 사람 이름, 받는 사람 이름, 그리고 제목은 EUC-KR로 인코딩되어있다는 것을 알 수 있습니다.
그럼, 제대로 나오는 ②의 원문을 한번 보도록 하죠.
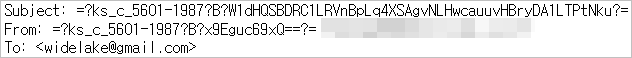
인코딩된 문자열로 되어있습니다.
둘간의 차이를 아실 수 있습니까? 네, 바로 제목과 보낸 사람 이름 필드에 문자 인코딩 셋이 지정되어있다면 글자가 깨지지 않습니다. ①의 메일에서는 “한글”로 제목과 이름을 기입했음에도 불구하고 문자 인코딩 셋을 지정하지 않았고, 유니코드(UTF-8) 기반인 Gmail에서 EUC-KR로 인코딩된 글자를 유니코드로 디코딩하려다보니 저렇게 깨져보이는 현상이 나타난 것입니다.
그러나 ②의 메일에서는 제목과 이름에 들어있는 문자들이 KSC5601-1987로 인코딩한 문자열이라고 지정하였습니다(=?ks_c_5601-1987?B? ~ ?=). 이 문자 인코딩 셋의 지정 여부 때문에 글자가 깨지고, 깨지지 않는 차이를 나타내는 것입니다. 그렇기 때문에, 이 문제는 기본적으로 받는 사람이 잘못한 것이 아니라 보내는 쪽이 잘못한 문제라고 할 수 있습니다.[note]기술적으로 본다면 외산 메일 솔루션을 도입해서 수정 혹은 그대로 사용하면서 인코딩 문제를 전혀 고려하지 않고, ‘국내 메일에서 잘 보이니까’라고 넘겨버리는 게 문제의 핵심입니다(외산 메일 솔루션이 개발단계에서 다국어 지원을 고려하는 일이 거의 없고, 또 그걸 한글화해서 판매하거나, 설령 자체적으로 개발한 국내 솔루션 업체도 이 문제를 심각하게 고려하지 않습니다. 대표적인 케이스가 넷퍼시의 대량 메일 솔루션입니다. 넷퍼시의 대량 메일 솔루션을 사용하는 업체의 DM은 100이면 100, Gmail에서 보낸 사람 이름이 깨져나옵니다). 그렇기 때문에 ‘원칙적으로’ 처리하는 메일 수신단에서 깨지면 보낸 쪽의 잘못은 생각하지도 않고 ‘받는 쪽이 이상하다’라고 주장하는 촌극이 벌어지는 것이지요. 메일 쪽에서는 상상외로 이런 경우가 많습니다.[/note] 보내는 쪽에서 반드시 수정을 해야하는 사항이며, 사견으로는 헤더부분에 문자 인코딩 셋을 지정하지 않는 것 자체가 ‘내가 메일을 제대로 보내지 않겠소‘라고 선언하는 꼴 밖에 되지 않는다고 봅니다.
그럼에도 불구하고 Gmail이 문자 인코딩 셋 문제에 있어 갈짓자(之) 행보를 보인다고 할 수 있는 것은 크게 세가지 이유가 있습니다.
첫번째, 이 문자 인코딩 셋이 지정되지 않은 문자열을 어떤 때는 자동으로 처리하여 제대로 보여주다가도, 갑자기 처리하지 않아 죄다 깨지게 하더니, 어느날 다시 제대로 처리를 해주다가 최근 들어 다시 처리를 해주고 있지 않습니다.
제가 작년 6월에 이 문제에 관련한 이삼구글님의 포스트에 남긴 댓글 중 일부입니다.
Gmail 처음 시작 당시에는 인코딩 셋을 자동으로 식별하여 처리해줬다가, 2004년말 즈음에 해당 처리과정 자체를 내렸었습니다. 그리고 2005년 봄부터 다시 처리가 되기 시작했었는데, 6월 15일 이후 다시 처리과정을 내린 것으로 보입니다(지금 제 gmail의 메일로 판단해볼 때). 결국 Google 쪽에서도 아직 인코딩 여부 판단에 대한 최종 결정을 내리지 못한 것으로 보입니다. 2년새 인코딩 정책이 3번이나 바뀐 셈이니까요.
2006년 6월 이후에도 계속해서 디코딩 정책이 바뀌었습니다. 이삼구님의 언급으로는 Gmail이 메일 원문 중 본문 문자 인코딩 셋(Content-Type: text/html; charset=euc-kr)을 참조하여 보여주나, 이것마저 제대로 되지 않을 경우 깨질 수 있다고 하셨지만, 제가 볼 때는 현재의 상태에서는 본문 문자 인코딩 셋이 지정되어있는 경우에조차 제목과 이름 부분의 문자 인코딩 셋이 존재하지 않는 경우 깨지고 있습니다.
두번째, 똑같이 제목과 이름에 문자 인코딩셋이 누락되었는데도 불구하고 제대로 출력되는 경우가 있습니다. 대표적인 케이스가 링크프라이스입니다.
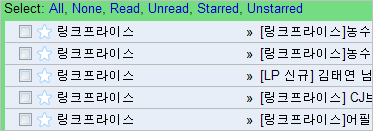
위의 이미지를 보시면, “링크프라이스”라는 보낸 사람 이름과 제목이 모두 정상적으로 출력됩니다. 그러나 원문을 한번 보겠습니다.

제목과 이름 부분에 문자 인코딩 셋이 지정되어있지 않습니다. 똑같은 메일인데, 누군 제대로 나오고 누군 깨져나오는 불일치가 발생하는 것입니다.
세번째, 문자 인코딩 셋이 지정되어있지 않아 글자를 깨져나오도록 한다면 제목도 똑같이 깨져나와야합니다. 그런데 Gmail은 그렇게 처리하지 않습니다. 보낸 사람 이름은 깨져나오도록 하더라도 제목은 제대로 나옵니다.
![]()
위의 예 ①번에 든 이니시스의 메일입니다. Gmail이 문자 인코딩 셋을 지정하지 않은 문자에 대해 별도 디코딩 처리를 하지 않고 그대로 출력하겠다고 정책을 정했다면 제목도 깨져나와야합니다. 이니시스의 메일은 제목도 문자 인코딩 셋을 지정하지 않았기 때문입니다.
만약 사용자의 불편함을 덜어주기 위해서 제목은 제대로 출력하기로 했다면 일관성이 없습니다. 그렇다면 보낸 사람의 이름도 제대로 출력해줘야할 것이고, 문자 인코딩 셋을 지정하지 않는 것에 대해 별도 처리를 해주지 않기로 했다면 제목도 깨져나와야합니다. 그러나 Gmail은 그렇게 하지 않았습니다. 일관성 측면으로 본다면 국내 포털 웹메일 모두와 Hotmail(Live Mail), Yahoo! Mail은 모두 제목과 보낸이를 공평하게 대합니다. 둘다 깨지던지, 둘다 깨지지 않습니다.
물론, 제목은 메일의 본문의 일부로 보니까 제대로 나오는 것 아니냐, 라고 할 수도 있겠습니다만, 엄연히 제목을 표시하는 subject 필드는 메일의 Header에 속하는 영역입니다(RFC2822). 똑같이 헤더에 속하는 필드가 어떤 것은 처리되고 어떤 것은 처리되지 않는 것 자체가 말이 안되는 겁니다.
별거 아닌데 왜 그러냐!이러실 수 있습니다. 보낸 사람 이름이 깨져나와도 불편할 것 없습니다. 하지만 Gmail이 한국어 버전을 지원하고 한국 서울 지사를 설립하는 와중임에도 불구하고 언어 리소스 문제에 대해 이렇게 갈짓자(之) 행보를 그리면서 어설프게 한다면 틀림없이 일반 사용자를 공략하는 데에는 실패할 겁니다(구글 한국어 리소스의 문제는 하루 이틀 일이 아닙니다만). 인터페이스의 어려움(뭐, 메일 바닥에서는 간편하면서도 기능적인 인터페이스로 여기는 성향이 있습니다만 일반 사용자의 관점에서 말입니다)은 차치하고라도 말입니다. 쓰는 사람 입장에서 불편하다면, 그것은 별거 아닌게 아닙니다.
특히 구글이라면 말이죠. ⓣ
좋은 글 잘 봤습니다.
저의 관점은 약간 다릅니다.
물론 지메일의 디코딩 정책(?)에도 문제가 있지만 원론적인 책임은,
바로 인코딩을 할 줄 모르는 발송 업체가 잘못된 거죠.
그럼.
다르지 않습니다. 저도 본문 중에서 “이 문제는 받는 사람이 잘못한 것이 아니라 보내는 쪽이 잘못한 문제라고 할 수 있습니다.”라고 얘기했으니까요.
제가 지적한 건 구글이 인코딩 정책을 너무 자주 바꾼다는 거죠. 깨지게 하던, 꺠지지 않게 하던 기준을 정했으면 끝까지 원칙을 밀고 나갔어야하고, 최소한 한두번 변경으로 그쳤어야합니다. 그런데 일년에 2, 3번씩 정책을 변경한다는 것 자체가 일관성이 없다는 걸 반증하고, 또, 적어도 Gmail 개발쪽에서는 다국어 처리에 그렇게 유도리있게 대응하지 못한다는 것을 뜻합니다.
제 포스트의 요점은, 기술적인 면보다는 정책적인 면이죠. 디코딩을 해줄꺼면 해주고, 말꺼면 말라는 얘기입니다. -_-)a
너른호수님의 말씀에 동감합니다.
한국 사용자들을 공략하려면 그것은 기술적인 측면이 아니라 정책적인 측면이 강하리라 생각됩니다.
기술이야 어쨌든..(그건 제공하는 회사들의 문제일테니까요..)
사용자들은 눈에 잘 보이면 되는 것일테니까요..;;
그러게요. “사용자들은 눈에 잘 보이면 되는 것”이라는게 기획자 입장에서는 상당한 딜레마입니다. 흑.
문자셋의 인코딩,디코딩 문제는 참 골치아파요. 모든 페이지가 유니코드(주로 UTF-8)를 사용하면 좋을텐데, 그렇지 않은 경우가 더 많으니 트랙백이나 페이지 긁어오기할 때도 문제고, 한글 파일 이름으로 된 주소나 파일명도 보이지 않는 경우가 많으니까요.
한국 웹사이트에 유니코드가 완전히 도입되려면 시간이 좀 많이 소요될 듯 하네요.
뭐 트랙백에서 글자깨지는 문제는 왠지 네이버 블로그가 생각이 나는군요. ㅋ
갈짓자..표현 정확하십니다;;
이건 모,, 일관된 정책이 아니니-_-a
아예 안 되면 그러려니 할텐데
되다 안 되다를 반복하니orz
정책 일관성이 없다는게 좀 그렇죠?
Pingback: 오선지위의 딱정벌레
전 그냥 평범한 이용자라서 포스트 내용을 제대로 이해하진 못했지만,
그니깐,,,gmail측에서 정책을 바꾸지 않는 이상 이용자 스스로 어떻게 한다고 해서 되는 문제는 아니라는 거죠?
저만의 문제는 아니라는 데서 위안??은 얻었으나, 아무런 해결책이 없다는 점에선 답답하네요.
전 은근히 저 문제가 신경쓰이고 불편해서요..
사용자가 어떻게 해서 할 수 있는 문제가 아니니까요.. ㄷ갑갑한 일이죠. ;ㅁ;
Pingback: 오선지위의 딱정벌레
‘정책’ 같은 무슨 거창한 문제가 아니라, 단순한 ‘버그’인 것 같군요.
정책의 문제라면 일부 SMTP 서버 (qmail었는지, exim이었는지 기억이 잘 안 나는군요)가 하듯이 RFC 2822가 금지한 헤더 필드에 들어 있는 8bit 문자를 몽땅 ?로 바꿔 버려야겠지요. EUC-KR로 인코딩된 8bit 바이트열을 ISO-8859-1로 인식해서 (UTF-8로 인식하는 게 아닙니다 !!!!) 지금처럼 깨져 보이게 할 것 같지 않군요. 리눅스나 프리비에스디를 쓰신다면 그 ‘암호 같은’ 문자열을 복사해서 UTF-8 로캘 하의 터미널에서 다음과 같이 해 보세요.
$ iconv -t ISO-8859-1 | iconv -f EUC-KR
<여기에 복사한 깨진 문자열을 붙여 넣으세요>
CTRL-D를 누르세요
<여기에 한글 문자열이 나옵니다>
$
왜 제목과 보낸 사람 이름을 다르게 처리하느냐? 둘은 좀 다르긴 하지요. RFC 2822에서 보면 제목은 단순한 헤더 필드이고, To, From,Cc 등은 ‘구조가 있는 헤더 필드’ (지금 RFC 2822를 보지 않고 기억에 의존해서 쓰고 있으므로, 용어가 정확하지 않습니다)이니까 이 두 가지를 처리하는 부분도 다르겠지요. 한쪽은 활용 가능한 모든 정보를 최대한 활용해서 무슨 인코딩인지 짐작을 제대로 하고 있고, 다른 한쪽은 아마도 그렇게 하지 않는 것이겠지요. 두말할 나위 없이 그렇게 하지 않는 쪽도 제목처럼 그렇게 해야 합니다.
두번째 문제 :
왜 똑같이 표준을 위반해서 헤더 필드에 인코딩을 명시하지 않았는데, ‘링크프라이스’는 제대로 나오고, ‘이니시스’는 제대로 나오지 않을까요? 신기하긴 합니다. 알 것 같기도 하고…… 🙂
어쨌든, 이 ‘버그’가 빨리 고쳐지길 바랍니다. 여러분이 큰 소리로 불평을 하셨으니까, 곧 고쳐지지 않을까요? 🙂
차라리 버그이길 바랍니다. 근데 단순 버그라고 보기에도 미묘한게.. 계속 왔다- 갔다- 보여줬다- 안 보여줬다- 이러니까 -_-; 뭐 솔직히 개발자가 아니고 운영하는 입장에서는 ‘장난치나-_-‘ 싶은 생각이 들기도 합니다. 같은 버그가 업데이트할때마다 나타났다가 롤백되었다가 하면 버그라고 봐주기에는 좀 짜증이 나지요. -_-;
여튼 quark님의 설명을 듣고 나니, 버그일 가능성이 높다는 걸 알게 되었습니다. 친절한 설명 감사합니다. ^^
* 두번째 문제는 진짜 모르겠습니다. 왜 그런지. -_-;
이 버그 고쳐진 것 같은데요. 최근 1주일 사이에 온 메일 가운데 RFC 2047을 위반한 게 3개 있었는데, 모두 다 보낸 사람 이름(보낸 사람 이름은 모두 한글 4음절 이하로 짧은 것이었습니다.)이 제대로 보입니다. 가장 최근에 온 것은 교보문고에서 온 것….
thunderbird 설정을 변경해서 RFC 2047을 위반하도록 한 후, gmail에 보내 보아도 역시 다 제대로 보입니다.
네 그렇네요. ^^ 한국시간으로 5월 23일 이후 수신된 메일부터는 정상적으로 표시되고 있습니다.
다시 저 버그가 등장하지 않길 바랄 뿐입니다 ㅡ_ㅡ;;
그나저나 RFC 2047 위반하는 프로그램 만든 사람들이 자기들 버그 고칠 인센티브가 하나 줄었군요. word press도 그 중의 하나인데…..
언제 시간 나면 패치를 제출하든지 해야겠군요.
정책 때문에 그걸 일부러 깨뜨리는 게 아니라는 제 말이 미덥지 않으신가 보군요. 🙂
제가 아는 구글의 정책 중 가장 중요한 것은 ‘사용자가 최우선이다’입니다. 문제가 된 경우는 보낸 이가 잘못한 것은 확실하지만 (메일 표준 위반), 수신측인 지메일이 보낸 이의 잘못에도 불구하고, From, To 헤더의 인코딩을 짐작하기에 필요한 충분한 정보가 다른 곳에 있습니다. 그러니까, 그 정보를 활용하지 않아서 사용자에게 불편을 초래하는 일은 구글의 기본 정책을 제대로 실천에 옮기지 못 했다는 점에서 ‘버그’입니다.
구글 엔지니어도 사람인 이상 다시 버그가 부활하지 않으리라는 보장은 없습니다. 하지만, 구글이 정말 제대로 소프트웨어 엔지니어링을 한다면 유니트 테스팅과 같은 버그 재발 방지책을 수립해 놓았겠지요.
아하, 기술적인 버그가 아니라 정책 실현에 있어서의 버그란 뜻이군요. 🙂